Centalized Log Analysis & Processing
Logging is always being considered as a fundametal and inherent part of any application, irrespective of the language and platform chosen.
By the question arises that "Why Logs are very important???"
Beacause I think it is the logs that help us get the real time impression of our application behaviour, i.e the user stimulus, the system responding to it, all the data that are being acted upon etc.
In a word the I can say not only the Lifecycle of the application but the human interactions too gets recorded while logging.
So Logging is basically the process of recording application actions and state.
The stream of events that gets captured while logging becomes a very important source of application's current state and the state to which it needs to be evolved.
Today Logging becomes the source of data analytics and data mines are emerging out from it which is helps us to make the application behave in a more intelligent manner.
But for all these to happen, we need to know What needs to be logged and How it needs to be logged.
Certainly we will not be discussing any of the above mentioned points out here.
Presently, I am exploring Spring Cloud, so what becomes more important is the analysis and at the same time processing of logs from various "Microservices" that interact with each other in an independent manner irrespective of the language or the framework chosen for the indivudual "Microservices"
So I think I am looking for Intelligent, Scalable, Centralized Log Processing framework with some user interface (if Possble). and believe me "ELK Stack" provides much more than that.
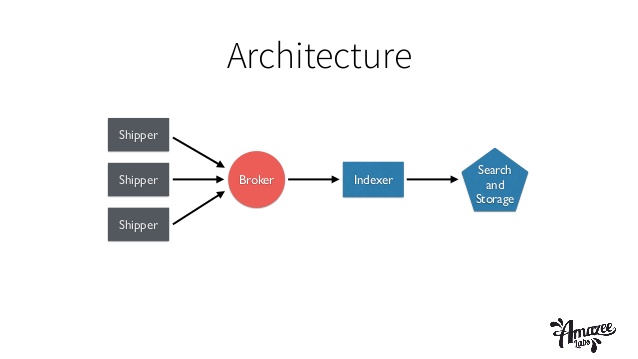 and it can now be visualized as(in a very simplified manner):
and it can now be visualized as(in a very simplified manner):
 So, the logfile (be it from any source) is passed first to logstash , which does all the processing required on the logfile (as described in the configuration file), from there the Elastic Search takes over which does indexing and other stuffs and finally passes the data to Kibana for Visual treat of various statistics.
So, the logfile (be it from any source) is passed first to logstash , which does all the processing required on the logfile (as described in the configuration file), from there the Elastic Search takes over which does indexing and other stuffs and finally passes the data to Kibana for Visual treat of various statistics.
The Elastic Search internally has got Lucene implementation. So, If I want to get a more elaborate look, the things would look like the following:
 Let me provide you a very basic working example of the ELK framework:
Let me provide you a very basic working example of the ELK framework:
input: where we specify the inputs to be processed. A varied types of input are allowed. Please Refer here for details. Here we have used 2 simplified file approach specifying start_position to be read from is from the beginning of the file, the default behaviour being tail(end). ignore_older being used to ignore reading older files that was last modified before the specified timespan in seconds. type is used as level and we will see its usage in Kibana.
filter:This section is used for Tokenizing, Parsing or Processing of the data read from input section. Here we have used the GROK filter.Please Refer here for details.
output:This is the section that provides the output of all the processing that has been done till now. For output we have used elasticsearch which runs at localhost:9200 and which ultimately forwards it too Kibana running at port 5601.Please Refer here for details. The configurarion that the elasticsearch will pust its output to Kibana running at port 5601 has been configured at elasticsearch.yml of the config folder.
I have the following:
1.logstash-2.3.1
2.elasticsearch-2.3.1
3.kibana-4.5.0-windows
Now we will open 3 command prompts and first we will start Kibana and elasticsearch from the corresponding bin directory and then will start the logstash from its bin directory using
Command -1
Command -2
Considering the configuration is ok, when we execute Command -1, the logstash after processing the log files passes it too elasticsearch, which again forwards it too Kibana for Visualization.
Altogether this has been a very basic walkthrough for ELK framework, much more could be accomplished with different plugins as provided in the Official ELK website.
So Happy Logging.....
Beacause I think it is the logs that help us get the real time impression of our application behaviour, i.e the user stimulus, the system responding to it, all the data that are being acted upon etc.
In a word the I can say not only the Lifecycle of the application but the human interactions too gets recorded while logging.
So Logging is basically the process of recording application actions and state.
The stream of events that gets captured while logging becomes a very important source of application's current state and the state to which it needs to be evolved.
Today Logging becomes the source of data analytics and data mines are emerging out from it which is helps us to make the application behave in a more intelligent manner.
But for all these to happen, we need to know What needs to be logged and How it needs to be logged.
Certainly we will not be discussing any of the above mentioned points out here.
Presently, I am exploring Spring Cloud, so what becomes more important is the analysis and at the same time processing of logs from various "Microservices" that interact with each other in an independent manner irrespective of the language or the framework chosen for the indivudual "Microservices"
So I think I am looking for Intelligent, Scalable, Centralized Log Processing framework with some user interface (if Possble). and believe me "ELK Stack" provides much more than that.
E ----> Elastic SearchSo the Architecture is somewhat like this:
L ----> Logstash
K ----> Kibana


The Elastic Search internally has got Lucene implementation. So, If I want to get a more elaborate look, the things would look like the following:

input {
file { path => "F:/My_Work/Spring_Cloud_Updated/Spring-Cloud-Eureka/logs/debug.log"
type => "Eureka_Logs"
start_position => beginning
ignore_older => 0
}
file { path => "F:/My_Work/Spring_Cloud_Updated/Spring-Cloud-Config/logs/debug.log"
type => "Config_Logs"
start_position => beginning
ignore_older => 0
}
}
filter {
grok { match => { "message" => "%{TIMESTAMP_ISO8601:logtimestmp} \[%{LOGLEVEL:level}\] \[%{USER:className} # %{WORD:method},%{INT:lineNo}\] \- %{GREEDYDATA:greedydt}"} }
}
output {
elasticsearch{hosts=>["localhost:9200"]}
#stdout { codec => rubydebug }
}
As we can see the configuration file consists of 3 sections:input: where we specify the inputs to be processed. A varied types of input are allowed. Please Refer here for details. Here we have used 2 simplified file approach specifying start_position to be read from is from the beginning of the file, the default behaviour being tail(end). ignore_older being used to ignore reading older files that was last modified before the specified timespan in seconds. type is used as level and we will see its usage in Kibana.
filter:This section is used for Tokenizing, Parsing or Processing of the data read from input section. Here we have used the GROK filter.Please Refer here for details.
output:This is the section that provides the output of all the processing that has been done till now. For output we have used elasticsearch which runs at localhost:9200 and which ultimately forwards it too Kibana running at port 5601.Please Refer here for details. The configurarion that the elasticsearch will pust its output to Kibana running at port 5601 has been configured at elasticsearch.yml of the config folder.
http.cors.enabled: trueTo see the whole operation in action we need to download zip of the following from
http.cors.allow-origin: http://localhost:5601
I have the following:
1.logstash-2.3.1
2.elasticsearch-2.3.1
3.kibana-4.5.0-windows
Now we will open 3 command prompts and first we will start Kibana and elasticsearch from the corresponding bin directory and then will start the logstash from its bin directory using
Command -1
logstash agent -f <NAME_OF_CONF_FILE>Since the CONF_FILE is being parsed by jRuby so it is required to check whether the file format is correct, as I really had a hard time in figuring wats wrong with my file as I could not find out anything with the syntax and later I found the identation causing problems So the config file can be check with :
Command -2
logstash agent -f <NAME_OF_CONF_FILE> --configTestUpon running Command -2, we will get the idea if the configuration file is ok or not.
Considering the configuration is ok, when we execute Command -1, the logstash after processing the log files passes it too elasticsearch, which again forwards it too Kibana for Visualization.
Altogether this has been a very basic walkthrough for ELK framework, much more could be accomplished with different plugins as provided in the Official ELK website.
So Happy Logging.....
Comments
Post a Comment